
前回、事前準備編としてグー・チョキ・パー撮影のための準備・設定、アノテーションについて書きました。
今回はメインのモデル学習について超絶丁寧に説明していきます!
モデル学習準備
グー・チョキ・パーのデータをGoogle Driveにアップ
事前準備編で作成した「撮影データ、アノテーションデータ、classes.txt」すべてをGoogle Driveにアップしましょう。
■フォルダ作成
・Google Driveにアクセス
・「新規」→「フォルダ」→(フォルダ名)「janken」→「作成」
これでjankenフォルダが作成できました。
■グー・チョキ・パーデータアップロード
・事前準備編で作成した「撮影データ、アノテーションデータ、classes.txt」をjankenフォルダにアップします
YOLOをインストール
ここからはGoogle Colabを使っていきます。
・Google Colabを開いて、ノートブックを新規作成します
・ノートブックに次のコマンドを入力・実行し、YOLO v5をインストールします。
!git clone https://github.com/ultralytics/yolov5■実行結果
・YOLO v5を利用するために必要なライブラリをインストールします
!pip install -r yolov5/requirements.txt■実行結果
設定ファイルの作成
学習を開始するときに学習対象となる画像などの場所を示した設定ファイル「janken.yaml」が必要になります。
設定ファイル自体は簡単なのでさくっとつくってしまいましょう!
▼janken.yamlファイルの記述内容
#学習データのフォルダ
train: /content/drive/MyDrive/janken
#テストデータのフォルダ
val: /content/drive/MyDrive/janken
#classes.txtの行数
nc: 18
#classes.txtの内容
names: ['dog','person','cat','tv','car','meatballs','marinara sauce','tomato soup','chicken noodle soup','french onion soup','chicken breast','ribs','pulled pork','hamburger','cavity','choki','gu','pa']データフォルダのマウント
Google ColabからGoogle Driveを参照できるように設定する必要があります。
Google Colabに以下のコマンドをコピペして実行しましょう。
from google.colab import drive
drive.mount('/content/drive')実行するとGoogle ColabからGoogle Driveを参照できるようになります。
下記の画像の通り、パスをコピーしてみましょう。

無事、contentという文字がコピーできましたね!
ここでコピーした文字を「train:」と「val:」にペーストしましょう。
classes.txtの情報
jankenフォルダにある「classes.txt」の内容をjanken.yamlに記述していきます。
記述する内容はclasses.txtの、
・行数
・内容
です。

設定ファイル
ここまでの情報で「janken.yaml」ファイルが完成です。
作成したファイルを「/content/drive/MyDrive/janken」配下に置きます。
いよいよ学習開始!
ようやくきましたよ!
以下のコードをGoolge Colabにコピペして実行しちゃいましょう!
%cd /content/yolov5
!python train.py --img 640 480 --batch 20 --epochs 300 --data '/content/drive/MyDrive/janken/janken.yaml' --name janken
これを実行すると、GPUを使っても2時間くらいかかります。
( たぶん、私のローカルPCだったら12時間以上かかりますが・・)
それが1/6くらいの時間になるので大変ありがたいのですが、注意が1つ。
パソコン休止状態と判断されてから90分間放置すると実行中でも強制終了させられるので、実行完了まではマウスを動かすなりちょくちょくと対応が必要です。
↓が実行結果です。
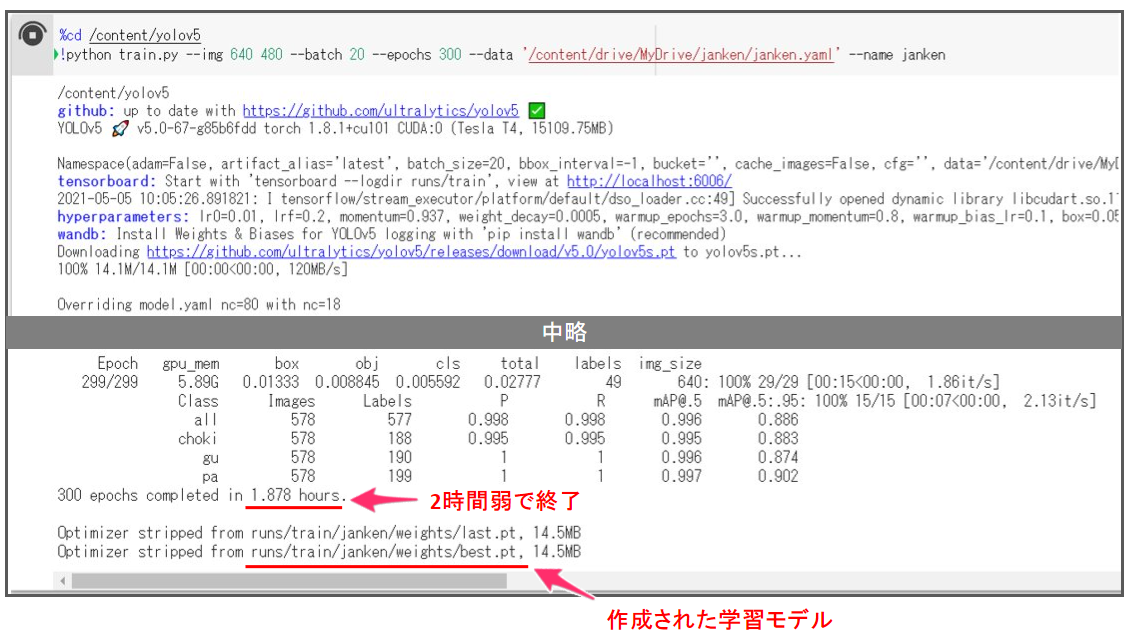
作成されたモデルはGoogle Colab上に作成されているため、リフレッシュされる前にローカル等にダウンロードしておきましょう。
作成したモデルを動かしてみよう!
Google Colab上で学習したモデルをローカルPCで実行して、グー・チョキ・パーをリアルタイムで判別できることを確認します。
環境構築
今回は、Anaconda上で動かしてみます。
Anacondaを起動し、以下のコマンドを実行します。
(yolov5) C:\Users\name>conda create -n yolov5 python=3.8
(yolov5) C:\Users\name>conda activate yolov5
(yolov5) C:\Users\name>git clone https://github.com/ultralytics/yolov5.git
(yolov5) C:\Users\name>cd yolov5
(yolov5) C:\Users\name\yolov5>conda install pytorch torchvision -c pytorch
(yolov5) C:\Users\name\yolov5>pip install -U -r requirements.txt次に環境が正しく構築されたことを確認するため、以下のコードを実行してください。
実行するとPCカメラが起動し、物体検出が開始されます。
(yolov5) C:\Users\name\yolov5>python detect.py --source 0グー・チョキ・パーモデルの実行
ここまで問題なければいよいよ作成したモデルの実行です。
Google Colabで作成したbest.ptを「 C:\Users\name\yolov5」直下に移動させてください。
移動できたら、以下のコマンドを実行します。
(yolov5) C:\Users\name\yolov5>python detect.py --source 0 --weight best.pt
実行!
認識率が若干低いのとたまに間違ってますね・・w
今回は「自分で撮った画像でモデルを作ってみよう!」が主旨なので、モデル精度はヨシとします^^
まとめ
今回は、3つの目的で記事を書いてきました。
・自分で画像を撮影して、オリジナルのモデルを作ってみよう
・Google Colabをつかってみよう
・機械学習アルゴリズムのYOLOをつかってみよう
いかがでしたでしょうか。
モデルのつくり方は本当に多岐に渡りますが「AIを体験してみる」という意味では、この記事を通して体験いただけたかなと思います。
いざ作ってみると「中の仕組みはどうなっているのかな?」とか「アノテーションが面倒だから他にやり方ないのかな?」とかいろいろ疑問が出てくると思います。
そのような疑問を解決できるような記事もどんどん書いていきますので、また興味があれば見てみてくださいね^^
ここまで読んでいただきありがとうございました。


コメント