
【考えれば考える程分からなくなった人向け】今度こそ機械学習とディープラーニングの違いがわかる!で書いた記事内容のコードを教えてほしい!とお声をいただいたので今回はコード中心に解説していきたいと思います^^
前回記事のサマリー
今回はコード解説版なので、詳しくは前回記事を参照してほしいですが、いきなりこの記事に来られた方のために少しだけ記事のサマリーを書いておきます。
『ディープラーニングは機械学習の一種で大きな違いは「特徴量を人が与えるか、特徴量を自動で抽出するか」だ。』んー・・分かるようでわからない・・・という人のために、犬・猫を判別するモデル構築を通じてその違いを書いていく、というものでした。
こんな方を対象にしています
・前回記事を読まれて「実際どんなコードを書いているのだろう?」と思われた方
・機械学習、ディープラーニングでの基本的なやり方がわからない
・ネット見てコピペしてるばっかりで、自分が何をしているかわからない
3つ目の「ネット見てコピペしてるばっかりで、自分が何をしているかわからない」という人は意外と多そうだと感じています。
コピペ → おー、できたー → 違うの試してみる → エラー
→ 調べてもよくわからない → 諦めて違うサイト探してコピペ・・・
ボクが最初こうでした 笑
そんな方にも少しでも勉強になるように書いていますので是非ご覧になってみてください。
機械学習編
必要なライブラリ(NumPy、Pandas、Matplotlib)を入れよう
まずはおなじみの”おまじない”と呼ばれる儀式です。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt今回はおまじないだけでは済ませないですよ!
まず抑えるべきポイント
NumPyは数値計算、Pandasはデータ解析、Matplotlibはグラフ描画をサポートしてくれるライブラリです。
機械学習、ディープラーニングをする上では必ず出てきます。
「まぁ、そうなんでしょうけど、パっとイメージできないんだよね・・・」
という方もいるかと思いますので、それぞれを関係性を簡単に確認しておきましょう。
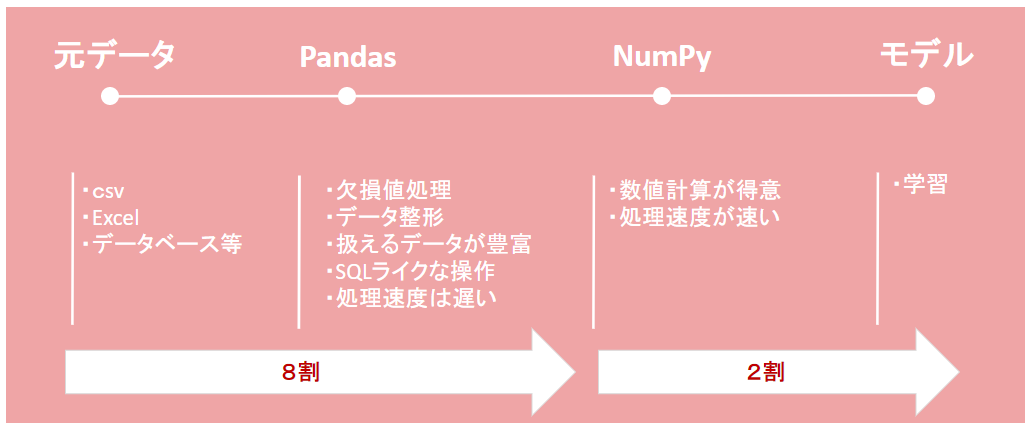
一言でいうと「生データをPandasでいろいろ加工・綺麗にして、NumPyでモデルが読める形に変えてあげる」感じですね。
ちょっと意味合いは違いますが、たとえばプレゼン資料をつくるときに資料の一部をグラフで表現するときを思い浮かべてください。最終的な形はパワーポイントかもしれないですが、元データを加工・整形・グラフ化するときにエクセルを使って処理し、最終的にパワーポイントに貼り付ける。なんてことをよくすると思います。感覚的にはそんな感じです。
データを格納する箱をつくろう(DataFrame)
次にデータを格納する箱を作ってあげます。
# 空のデータフレームを作成
# データフレームの特徴:異なる型を1つのデータフレームで処理できるため、データ前処理が容易
# データ収集(csvなど) → データ加工(Pandas) → 数値計算(NumPy) → 学習の順番で利用されることが多い
dog = pd.DataFrame()
cat = pd.DataFrame()箱(DataFrame)にデータを入れていこう
さきほどつくった箱にデータを入れていきます。
CSV等、元データがあればロードすればいいのですが、今回は元データがなかったので自分で作りました。
# 犬の平均体高、体長、体重、ヒゲについて標準偏差から500個分の身長データをランダムに生成
# np.random.normal:正規分布に従う乱数を生成する関数
# noemal:正規、random:乱数
# 引数(平均,標準偏差,出力数)
# 標準偏差:データのバラつきを示す指標
dog_height = np.random.normal(28.19,1.2, 500)
dog_length = np.random.normal(29.68,1.2, 500)
dog_weight = np.random.normal(7.5,1, 500)
dog_beard = np.random.normal(3,1, 500)今回やったデータのつくり方は別に覚えなくてもよいですが、一応説明しておきます。
やったことは「犬の体高(height)、体長(length)、ヒゲ(beard)、体重(weight)データを平均値と標準偏差を使ってランダムに500個生成」しています。
次も同じように猫のデータをつくっていきます。
# 猫平均体高、体長、体重、ヒゲについて標準偏差から500個分の身長データをランダムに生成
# np.random.normal:正規分布に従う乱数を生成する関数
# noemal:正規、random:乱数
# 引数(平均,標準偏差,出力数)
# 標準偏差:データのバラつきを示す指標
cat_height = np.random.normal(27.19,1.3, 500)
cat_length = np.random.normal(35,1.3, 500)
cat_weight = np.random.normal(5.5,1, 500)
cat_beard = np.random.normal(3,1, 500)いまつくった犬と猫のデータを箱にいれます。
そして、dog.head()で箱の中身を5行分、表示しています。
# 作った500個のデータをdogのデータフレームに格納
# head()でデータフレームに格納されている先頭5行分を表示
dog["height"] = (dog_height)
dog["length"] = (dog_length)
dog["weight"] = (dog_weight)
dog["beard"] = (dog_beard)
dog["animal"] = 0
dog.head()animalってどこからでてきたの?
はい、犬と猫を識別する区分として0:犬、1:猫として登録しています。
このようにデータ生成時に作っていなかった項目でも簡単に箱(DataFrame)に追加することが可能です。
猫も同じようにします。
# 作った500個のデータをcatのデータフレームに格納
# head()でデータフレームに格納されている先頭5行分を表示
cat["height"] = (cat_height)
cat["length"] = (cat_length)
cat["weight"] = (cat_weight)
cat["beard"] = (cat_beard)
cat["animal"] = 1
cat.head()ここまでつくったデータの中身を可視化しよう
先ほどまで作った箱にデータを入れてきました。
しかし、ただただ箱のデータを数値的に眺めても特徴がわからないので視覚的に見ていきます。
# 体高とひげの散布図
plt.scatter(dog[dog["animal"]==0]["height"],dog[dog["animal"]==0]["beard"],label="dog")
plt.scatter(cat[cat["animal"]==1]["height"],cat[cat["animal"]==1]["beard"],label="cat")
## X軸の範囲を指定
plt.xlim(20,50)
## Y軸の範囲を指定
plt.ylim(0,5)
## X軸の名前
plt.xlabel("height")
## Y軸の名前
plt.ylabel("beard")
## 凡例を出力
plt.legend()これを実行するとこんな図が表示されます。
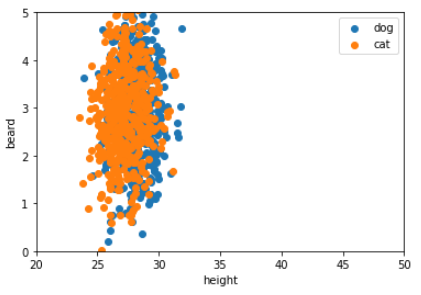
さっきつくったデータから表示したい項目を指定するだけでサクッと確認できるのはいいですね。
同じように体高と体長のデータも可視化してみます。
# 体高と体長の散布図
plt.scatter(dog[dog["animal"]==0]["height"],dog[dog["animal"]==0]["length"],label="dog")
plt.scatter(cat[cat["animal"]==1]["height"],cat[cat["animal"]==1]["length"],label="cat")
## X軸の範囲を指定
plt.xlim(20,50)
## Y軸の範囲を指定
plt.ylim(20,50)
## X軸の名前
plt.xlabel("height")
## Y軸の名前
plt.ylabel("length")
## 凡例を出力
plt.legend()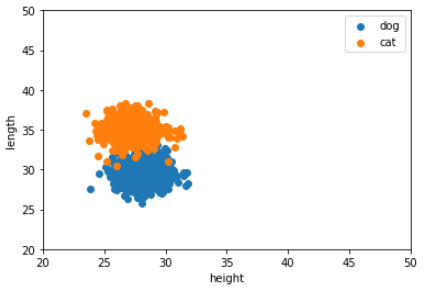
次に体長と体重を可視化してみます。
# 体長と体重の散布図
plt.scatter(dog[dog["animal"]==0]["length"],dog[dog["animal"]==0]["weight"],label="dog")
plt.scatter(cat[cat["animal"]==1]["length"],cat[cat["animal"]==1]["weight"],label="cat")
## X軸の範囲を指定
plt.xlim(20,50)
## Y軸の範囲を指定
plt.ylim(2,10)
## X軸の名前
plt.xlabel("length")
## Y軸の名前
plt.ylabel("weight")
## 凡例を出力
plt.legend()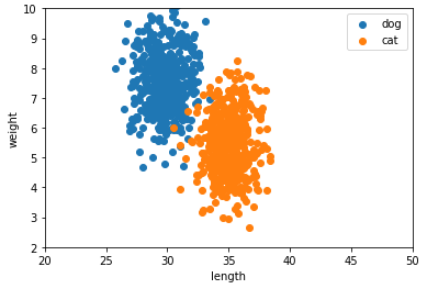
dogとcatの箱(DataFrame)を結合しよう
実際、モデルの学習時は以下のような準備をします。
①学習データ(今回でいうと犬と猫のデータ)と正解データ(今回でいうと”animal”の0、1の項目)を準備
②モデル精度を確認するための検証データ
今回、準備した犬と猫のデータ合わせて1,000件ありますが、そのうち800件を①、200件を②で分割して利用するといったような感じで進めます。
以下のコードはdogとcatでバラバラに作った2つ箱(DataFrame)をくっつけて1つの箱にします。
つまり、①の学習データと正解データが1つの箱に入っている状態です。
# dogとcatの2つのデータフレームを結合
dogcat = pd.concat([dog,cat])
dogcat1つの箱にくっつけた中身はこんな感じです。 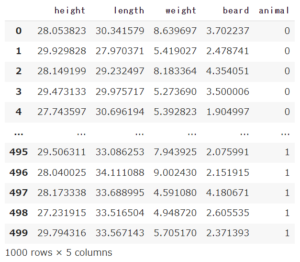
学習データに利用する項目を抽出しよう
今回は体長(length)と体重(weight)を特徴としてモデルに学習させるので、dogcatのDataFrameから体長(length)と体重(weight)のみを抽出します。
# dogcatから体長(length)と体重(weight)のみを抽出
x = DataFrame(dogcat.loc[:, ['length', 'weight']])
x.head()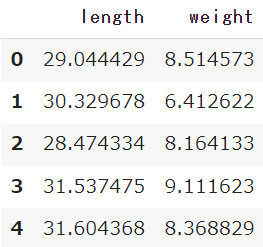
正解データに利用する項目を抽出しよう
次に正解データの作成をします。今回でいうと”animal”の0、1の項目をdogcatのDataFrameから抽出します。
# dogcatからanimalのみを抽出
y = DataFrame(dogcat["animal"])
y.head()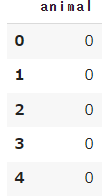
学習データと検証データに分割しよう
ここまでで、学習データ(体長(length)と体重(weight))と正解データは準備できましたので、次はこの塊になっているデータを学習データ:検証データ=8:2に分割します。
モデル構築において、学習データと検証データの割合が何対何でないといけないという決まりはありません。今回は8:2として進めます。
データ分割は「scikit-learn(サイキット・ラーン)」という機械学習ライブラリにtrain_test_splitという関数がありますのでそれを利用すればサクッと学習データと検証データに分割することができます。
train_test_split(x,y,test_size=0.2)はxとyのデータからテストデータを20%作ってねという指定になります。
# 学習データ・学習用正解ラベル、検証データ・検証用正解ラベルを作成
# train_test_split:学習データ:検証データを8:2に分割(test_sizeを20%に指定しているため)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
# 学習データ数
print(x_train.shape)
print(y_train.shape)
# 検証データ数
print(x_test.shape)
print(y_test.shape)
print文で分割したデータの数を出力させましたが、指定の通り8:2になっていますね。
いよいよ学習です!
いやー、長かったですね。。笑
ここからはいよいよ学習です!一瞬で終わります。
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
lenwei_model = LinearSVC()
# モデルに学習させる
lenwei_model.fit(x_train,y_train)
#モデルに予測させる
lenwei_predict = lenwei_model.predict(x_test)
lenwei_score = accuracy_score(y_test, lenwei_predict)
print('体長と体重の正解率:{}'.format(lenwei_score), sep='\n')![]()
はい、終わりです。前処理が大変、ということを体験いただけたかと思います。
少し解説していきますね。
前回も少しフレーズとしては触れていますが、機械学習アルゴリズムとしてはLinear SVCを利用しています。
Linear SVCとはクラス分類を行うときに利用するアルゴリズムです。今回は犬と猫を分類するので、Linear SVCを利用しました。
fitでモデル学習、predictでモデルを使った予測を行います。
つまり、先ほど学習データとして分割したx_train,y_trainをfitで学習させ、構築したモデルにx_testをインプットし、predictで予測させます。予測結果の精度をaccuracy_scoreで出力させています。
機械学習編まとめ
いかがでしたでしょうか。今回は機械学習編としてお送りしましたが、モデルの作成は一瞬で、前処理が大変・・・ということを体感いただけたのではないかと思ってます。
もちろん、今回は超絶シンプルなお題なので、これくらいで済んでいますが、本格的に活かそうと思ったときは、データ分析、欠損値補完、データ加工・・などなどたくさんの検討し、モデル構築→検証を繰り返さなければなりません。
実際のところは何かやろうとしても、対象データが全然ない・・なんてことはザラなので、まずはデータ取得をしなければならず、データを集めるだけで何か月もかかってしまうことも多々あります。
「AI」というキーワードは一見華やかなフレーズですが、現実は意外と地味な作業が多いもんです^^;
次回はディープラーニング編をお届けしたいと思います!


コメント