
【考えれば考える程分からなくなった人向け】今度こそ機械学習とディープラーニングの違いがわかる!で書いた記事内容のコードを教えてほしい!とお声をいただいたので今回はコード中心に解説していきたいと思います^^
前回記事のサマリー
今回はコード解説版なので、詳しくは前回記事を参照してほしいですが、いきなりこの記事に来られた方のために少しだけ記事のサマリーを書いておきます。
『ディープラーニングは機械学習の一種で大きな違いは「特徴量を人が与えるか、特徴量を自動で抽出するか」だ。』んー・・分かるようでわからない・・・という人のために、犬・猫を判別するモデル構築を通じてその違いを書いていく、というものでした。
こんな方を対象にしています
・前回記事を読まれて「実際どんなコードを書いているのだろう?」と思われた方
・機械学習、ディープラーニングでの基本的なやり方がわからない
・ネット見てコピペしてるばっかりで、自分が何をしているかわからない
3つ目の「ネット見てコピペしてるばっかりで、自分が何をしているかわからない」という人は意外と多そうだと感じています。
コピペ → おー、できたー → 違うの試してみる → エラー
→ 調べてもよくわからない → 諦めて違うサイト探してコピペ・・・
ボクが最初こうでした 笑
そんな方にも少しでも勉強になるように書いていますので是非ご覧になってみてください。
ディープラーニング編
前回は機械学習編のコード公開・解説をしましたが、今回はディープラーニング編です。
機械学習のようにデータの特徴をみてどの項目が判別に影響するのか・・・なんてことは一切しません。
なぜなら、ディープラーニングは「自動的に特徴を捉えて、勝手に学習してくれる」からです^^
賢いですね~。
では早速みていきましょう!
必要なライブラリを入れよう
機械学習編と同様、まずは必要なライブラリを入れていきます。
import numpy as np
import matplotlib.pyplot as plt
import os
import cv2
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Conv2D, MaxPooling2D, Flatten
from keras.optimizers import Adam
from keras.utils.np_utils import to_categorical
from tensorflow.keras.datasets import cifar10 # tf.kerasを使う場合(通常)・・・。
なんか、急に多いな!
はい!めげずにやっていきましょう!
NumPy・Matoplotlib
は前回説明しているので前回記事をご覧ください。
os
指定フォルダ配下のファイル名取得やパス結合を行うとき等、OSに依存する機能を利用するためのモジュールです。
フォルダ構成を例に説明します。

▼テストフォルダ直下にあるフォルダやファイルを確認したい場合
os.listdirというコマンドで指定フォルダ直下にあるフォルダやファイルを確認することができます。
※DATADIRにはあらかじめ ” ./drive/MyDrive/test ” を指定しています。

ちゃんとtestフォルダ配下のフォルダとファイルが出力されましたね。
▼ファイルパスを取得したい場合
testフォルダ配下にdogフォルダとcatフォルダがありましたね。dogおよびcatフォルダの配下にはファイルを一つずつ配置しています。
./drive配下のファイルパスを取得したい場合はこのようにします。
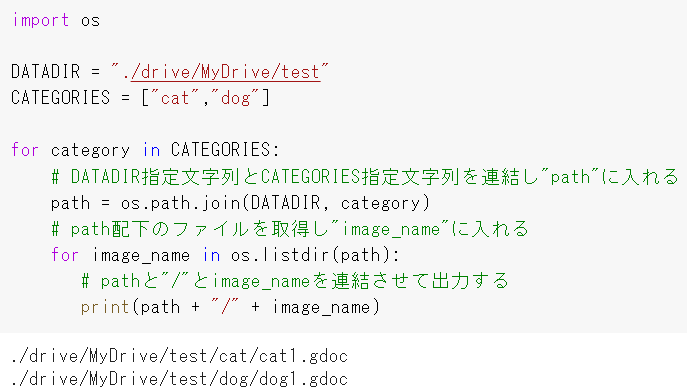
一つの例として、フォルダに入れておいた画像ファイルから学習データと正解ラベルを紐付けながらモデルに与えるデータを生成していくときなどにこのようなロジックを利用します。
cv2
OpenCVと呼ばれるライブラリをインポートします。OpenCVは画像や動画を処理するのに必要な機能を提供してくれるライブラリです。今回の記事では元画像をリサイズしたり、色変換したりするのに利用しています。
画像を扱う人はほぼほぼ通る道かと思います。
Sequential
今回は「モデルはSequentialで書きます」というのを指定(import)しています。
TensorFlowにおけるモデルの書き方には大きくわけて3つあります。
・Functional API
・Subclassing
Sequential
“連続的な”という意味を持つSequential。その名の通り、上から下に連続的に直列でつないでいく処理によりモデルを実現させています。
ディープラーニングを勉強し始めた人が「えっ、ディープラーニングってこんなに簡単にできるの?」と驚くくらいシンプルな構造です。
少しコードを抜粋してみてみましょう。

model = tf.keras.Sequential()で「このモデルはSequentialで記述するよ」と宣言しています。
そのあとはaddで層をひたすら追加していけばモデルを作ることができます。
シンプルで理解しやすい構造ですが、1入力1出力のため複雑なことができません。例えば、ある画像の予測結果を「犬か猫」に分類し、1つの結果として出力が可能ですが、その犬(または猫)が「男の子か女の子か」までは表現できない、という意味です。
Functional API
先ほどSequentialで説明したデメリットをクリアできるのがFunctional APIです。
Functional APIでは複数入力・複数出力のモデルを構築することができるため柔軟性があります。
先ほどは犬・猫で例えましたが、他で例えると「顔画像から年齢・性別・感情を予測」みたいなことも可能になります。
Subclassing
紹介するモデルの書き方で一番、自由度が高く記述できる書き方がSubclassingです。
SequentialやFunctional APIは静的モデルと呼ばれており、モデルの構造を動的に変更させることはできませんが、Subclassingはモデルを動的に変更することが可能です。
俗にいう ” Define by Run “ と呼ばれる構造体のことです。
・・な、なるほど・・
と、理解できた方はすごいなぁと思います。
私は「動的?」「具体的にいうと?」「どんな時に使い分けるの?」という疑問ワードがいっぱい出てきて、「あ~、なるほどね」ってなるまで1週間くらいかかりました 笑
今回はコード解説がメインなのでSubclassingの詳細については別記事とし、ここでは触れませんが「条件によって処理を分岐させ、学習ロジックを分けたい場合」にはSubclassingで記述します。
・モデルの計算結果によって、適用する活性化関数を変えたい場合
層の部品
続いては層の部品をインポートしていきます。
from keras.layers import Dense, Flatten, Conv2D, Activation, MaxPooling2D, Dropout
Dense
Denseは全結合層という意味で、全入力値に重みを掛け、バイアスを足した結果のニューロンの集合体を全結合層と言います。
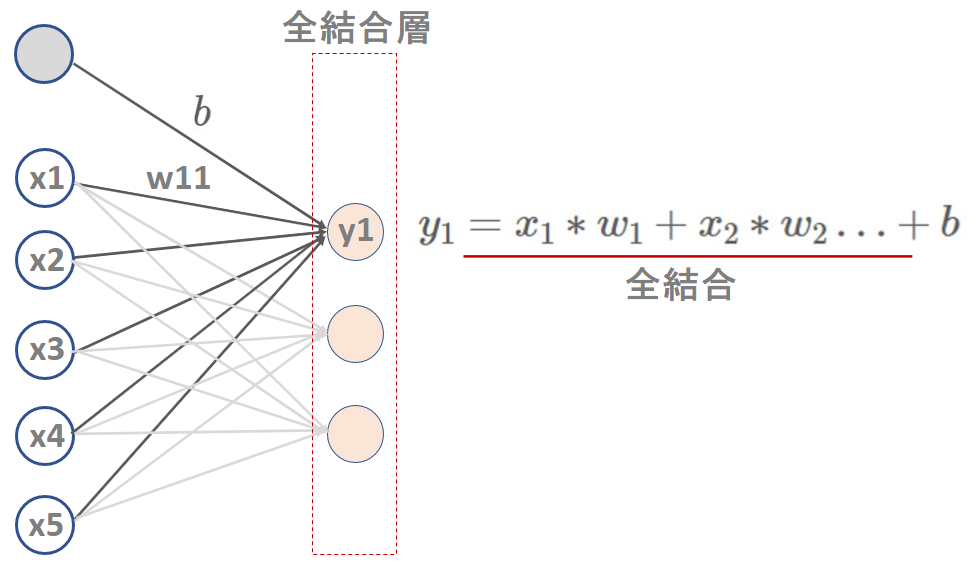
別の言い方として、Affine(アフィン)やFC層という呼び方で説明されることもありますが、いづれも同じものを指しています。
全結合層を利用するには入力データは1次元データとして与えなければならないという制約があります。
のちにソースコード解説で詳細を触れます。
Activation
Denseの説明でニューロンの計算式を示しました。
\begin{align}
y_1&=w_1*x_1+w_2*x_2+・・・+b
\end{align}
この計算された$y_1$をある値に変換して出力する役割をもったものを活性化関数(Activation)と言います。
なぜ、一度計算した$y_1$を変換する必要があるの?という疑問をもたれる方もいると思います。
その疑問を解決するには、まず$y_1$がどのような性質をもった式なのか、というのを抑えましょう。
\begin{align}
y_1&=w_1*x_1+w_2*x_2+・・・+b
\end{align}
これは次数が1次なので、1次関数です。言い換えると線形であると言えます。
グラフでイメージするとこんな感じの”直線的”な性質を持つのが線形です。
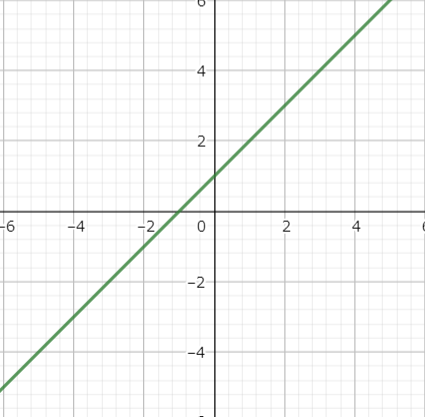
ここまででわかるのが、$y_1$は線形であるということです。
理解を深めるために以下の図を見てください。
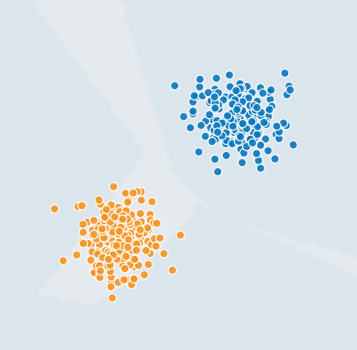
オレンジとブルーの境界値はどこを考えてみましょう。簡単ですね。
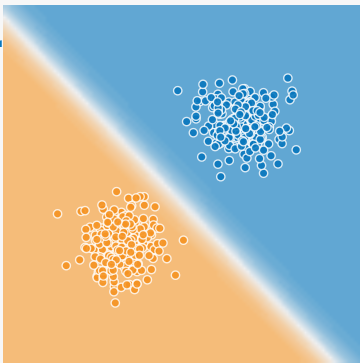
こんな感じです。
直線で分離可能なものを” 線形分離可能 “と言います。
では、次は線形分類可能でしょうか?

どう考えても無理ですね。
オレンジとブルーを分けた場合、こんな感じになります。

このようにブルーの中心に円を描くように境界値を引くことで、オレンジとブルーを分離することが可能になりました。
つまり ” 非線形 ” であれば分離可能になったということです。
この線形を非線形に変換してくれるのが活性化関数です。
ちなみに今回はReLUという活性化関数を利用しました。活性化関数は他にもあり、それぞれ性質をもっていますが、ここで重要なのはその性質の違いではなく、線形を非線形にする役割として活性化関数を利用しているということ抑えてください。
Flatten
N次元を1次元に変換する関数です。先ほど、全結合層は1次元の入力データで利用する必要がある、と説明しましたが、Flattenを利用することで簡単に1次元データに変換することができます。
Conv2D
畳み込みニューラルネットワーク(CNN)で2次元データを畳み込むために利用する関数です。
画像を扱うディープラーニングといえばCNN、というくらい超有名なものです。
何をしてくれる関数なのかというと「与えられた画像データをもとに、その画像が持つ特徴を抽出してくれる関数」です。
正確にいうと「画像データに対してフィルタ(またはカーネル)をかけて特徴を抽出・圧縮」します。
言葉で言われてもピンとこないと思うので、少しだけ例を用いて補足します。
※あくまで直感的にイメージを掴んでもらうためですので、正確性に欠けることはご了承ください※
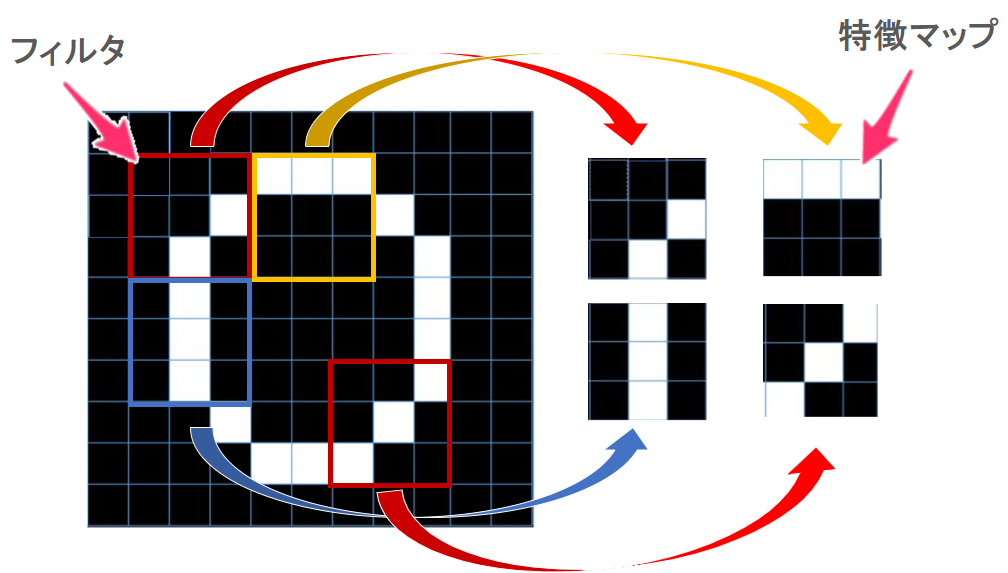
今回、インプットする画像はゼロとします。
画像というのは画素の集合体(小さな画像の集まり)で、1つ1つの画素に色情報を持つことで色の濃淡を表現しており、物体を表現することができています。
この画像の特徴を捉えるためにある一定の大きさに切り取って、切り取った局所的な部分の特徴を学習します。
この「一定の大きさに切り取る」ためにフィルタを用いて処理をします。フィルタを用いて抽出した特徴を特徴マップとして保持します。
画像に対してフィルタを用いて特徴を抽出する・・・このように繰り返しフィルタをかけることで画像全体の特徴を捉える行為ことこそがConv2Dの役割です。
MaxPooling2D
Conv2Dで画像を畳み込んだ結果に対してフィルタ(カーネル)をかけ、画像の特徴を粗く捉えるための役割をもっています。
言葉だけではイメージがつかないと思いますので図で補足します。
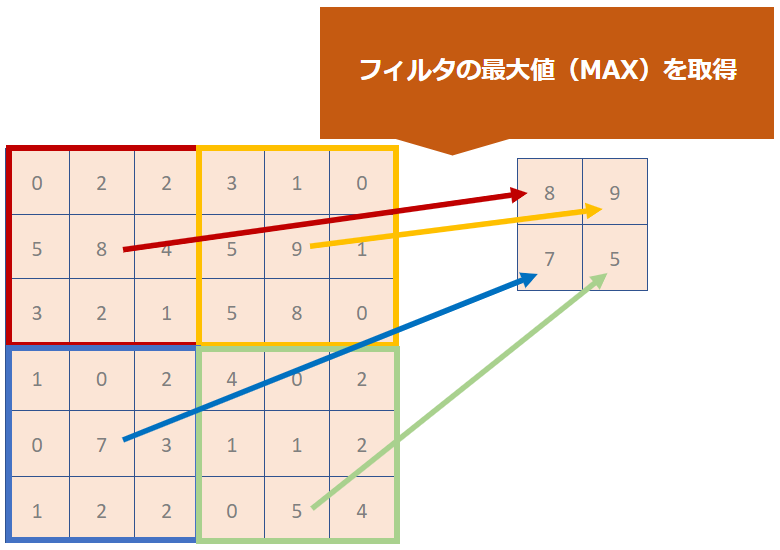
Conv2Dのの時と同様にフィルタ(カーネル)を利用します。
そのフィルタの範囲で一番大きな数字を抽出した結果を出力していきます。
これがMaxPooling2Dです。最大値を抽出するので「Max」なんですね。
なんのために最大値だけを抽出するのか?という点についてですが、それは「画像の位置ズレを吸収する」ためです。
例えば、リンゴの写真を2枚撮影したと仮定しましょう。
1枚目と2枚目を重ね合わせたとき、リンゴの位置が完全に合ってる確率は少ないですよね。

極端ですが、これくらい位置がズレても人間の目にはどちらもリンゴであることがわかります。
人間には簡単に見分けることができても、コンピューターには難しいこともたくさんあります。
それは、思考の応用がきかないからです。
位置がズレても判別対象をしっかり特定するための工夫としてプーリング層による最大値の取得が行われます。
先ほど利用した6 × 6マスの図を1マス右にずらして検証してみましょう。
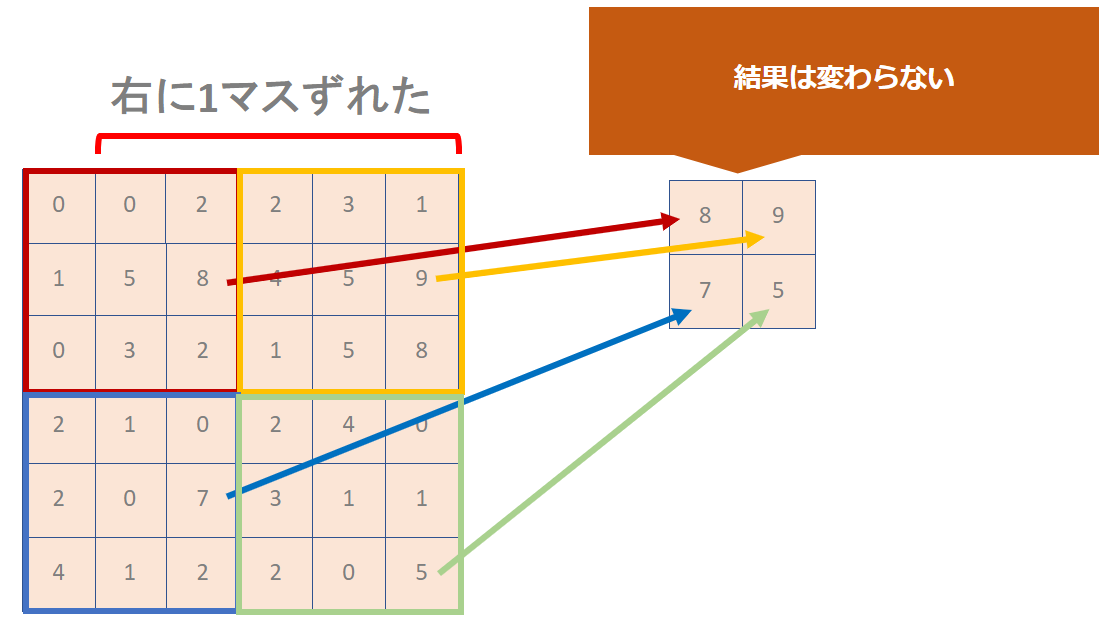
特徴を粗く捉えておくことで、このように画像位置がずれても判断が可能になるよう工夫されているのがプーリング層です。
今回はフィルタ(カーネル)の最大値を取得するMaxPoolingを紹介しましたが、平均値をとるAveragePoolingという関数も存在します。
Dropout
Dropoutは過学習を防ぐために利用されるものです。
ディープラーニングを学習し始めた頃に聞く「過学習」です。
具体的に何をしているのかというと、ランダムにニューロンを無効化しています。
model.add(Dropout(0.5))で50%のニューロンをランダムに無効化します。model.add(Dropout(0.2))で20%のニューロンをランダムに無効化します。今回はここまで。。
呪文の説明が思った以上に長くなっています。。
読んでくださった皆さんも疲れたと思いますので、続きは次回にします。。


コメント